Weight Space Representation Learning via Neural Field Adaptation
We show that constraining neural field weight optimization to a structured low rank subspace via a pretrained base model and multiplicative LoRA enables weights themselves to serve as semantically meaningful data representations for both discriminative and generative tasks.
Key Insight
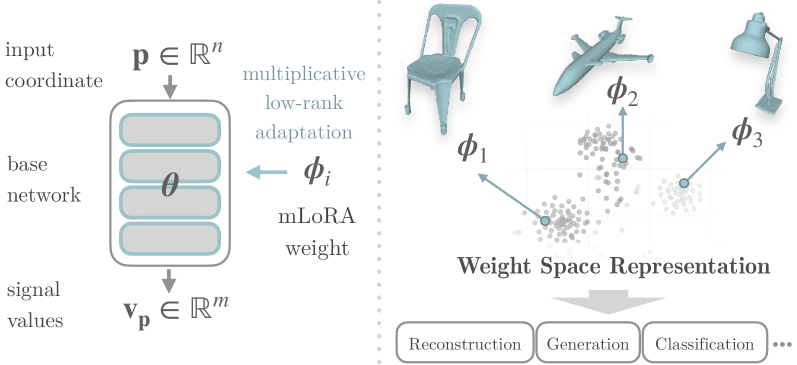
Overview of the weight space representation pipeline. Each data instance is encoded as a set of low-rank weight deltas relative to a shared base model.
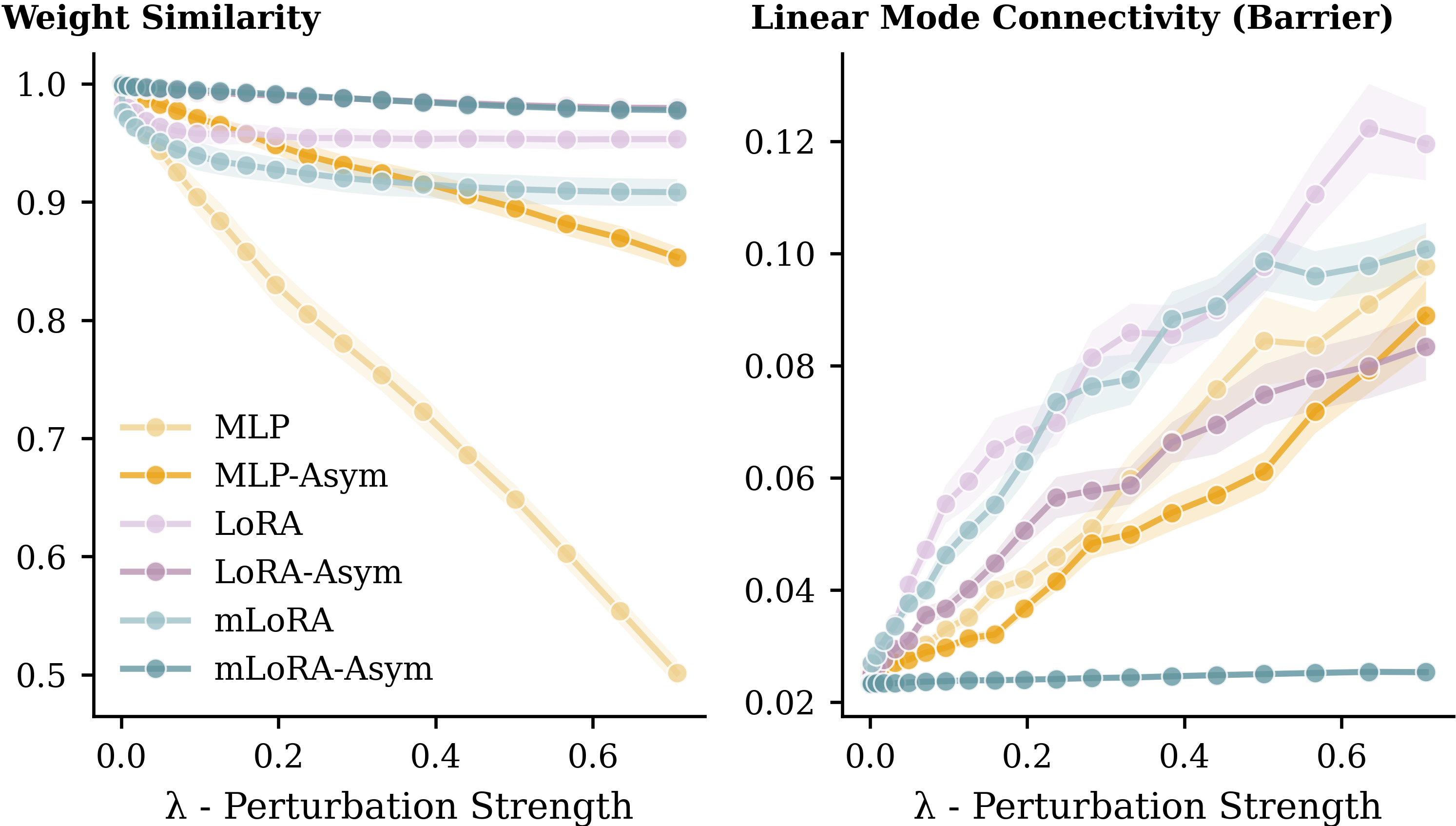
Weight space structure analysis. mLoRA-Asym weights exhibit strong linear mode connectivity, a key geometric property that enables high-quality generation.
Method
The core challenge: neural network weights have permutation symmetry. Reordering neurons produces a different weight vector encoding the exact same function. This makes the weight distribution wildly multi-modal, and learning over it nearly impossible.
Fix: Share a single pre-trained base model. All instances reference the same neuron ordering. Symmetry eliminated.
(AG)(G⁻¹B) = AB This gives a GL(r) fold equivalence class per function.
Fix: Asymmetric masking.
Our solution for permutation symmetries:
Results

Qualitative generation results. mLoRA-Asym produces sharper, more coherent outputs compared to baselines across both 2D and 3D data.
Reconstruction Quality
| Method | #Params | FFHQ PSNR ↑ | #Params | ShapeNet CD ↓ |
|---|---|---|---|---|
| Standalone MLP | 27,357 | 35.11 | 30,196 | 2.57 |
| LoRA (additive) | 27,395 | 35.2 | 29,696 | 3.10 |
| mLoRA-Asym (Ours) | 26,307 | 36.91 | 27,539 | 2.41 |
mLoRA-Asym achieves the best reconstruction quality on both 2D faces (FFHQ) and 3D shapes (ShapeNet).
Generation Quality (Latent Diffusion on Weights)
| Method | FFHQ FD ↓ | ShapeNet Multi FD ↓ |
|---|---|---|
| HyperDiffusion | 0.241 | 0.117 |
| mLoRA-Asym (Ours) | 0.073 | 0.026 |
Structured weight space geometry directly translates to generation quality: mLoRA-Asym reduces Fréchet Distance by over 3× on FFHQ and 4× on ShapeNet Multi compared to HyperDiffusion.
Discriminative Analysis: ShapeNet Classification
| Method | Logistic Regression Accuracy ↑ |
|---|---|
| Standalone MLP | 78.1% |
| mLoRA-Asym (Ours) | 90.0% |
A linear classifier achieves 90% accuracy over 10 ShapeNet categories, confirming that the weight space encodes semantic structure.
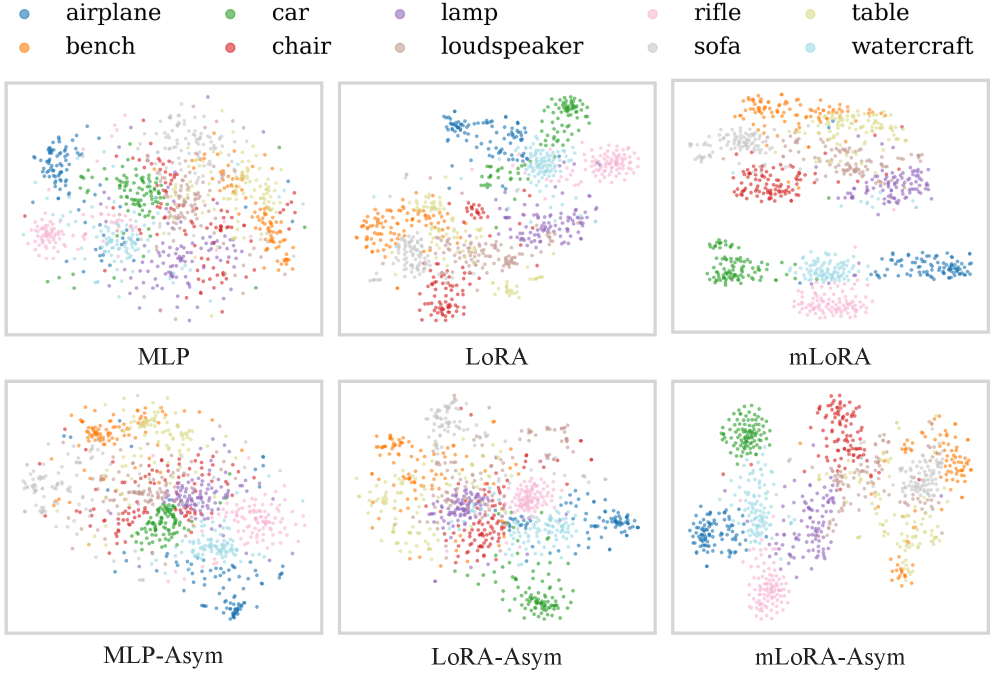
t-SNE visualization of weight representations. mLoRA-Asym weights form tight, well separated clusters per semantic category, demonstrating strong structure in weight space.
Citation
@inproceedings{yang2026wsr,
title = {Weight Space Representation Learning via Neural Field Adaptation},
author = {Yang, Zhuoqian and Salzmann, Mathieu and S{\"u}sstrunk, Sabine},
booktitle = {Proceedings of the IEEE/CVF Conference on
Computer Vision and Pattern Recognition (CVPR)},
year = {2026}
}