Subtractive Modulative Network with Learnable Periodic Activations
†School of Computer and Communication Sciences, EPFL, Switzerland
Abstract
Highlights
Method
SMN is inspired by classical subtractive synthesis from audio signal processing: a spectrally rich signal is generated first, then progressively shaped. Given a coordinate input, the network processes it through three interpretable stages:
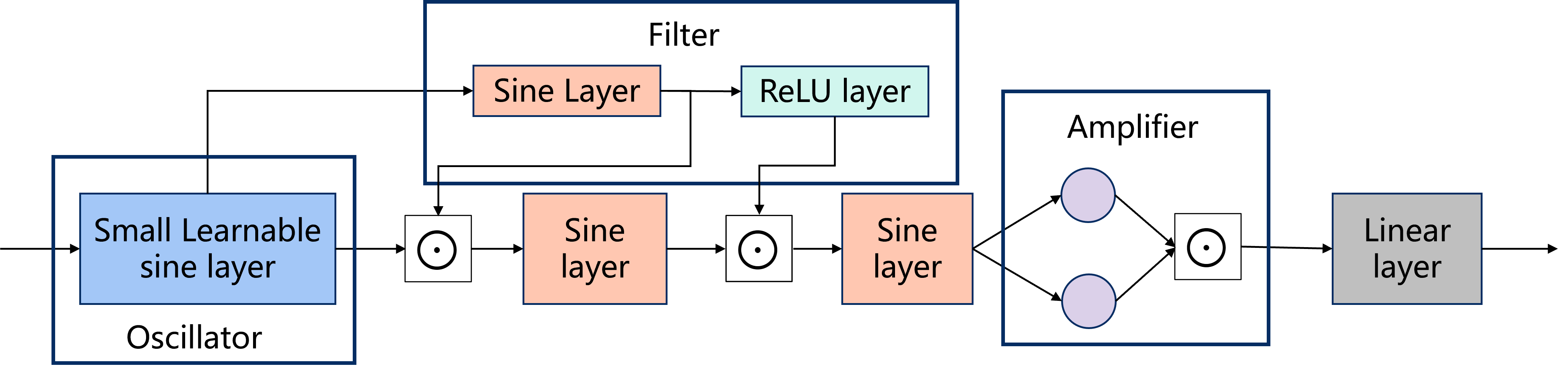
End-to-end architecture of the Subtractive Modulative Network, illustrating the Oscillator, multi-stage Filter (main and masking pathways), and the Amplifier (Self-Mask) stage.
Results
2D Image Representation
| Method | Kodak PSNR | DIV2K PSNR | Parameters | GFLOPs |
|---|---|---|---|---|
| MLP | 28.63 dB | 30.21 dB | 272,415 | — |
| RINR | 32.96 dB | 34.03 dB | 289,716 | — |
| SIREN | 33.65 dB | 33.73 dB | 272,703 | 214 |
| Gauss | 37.90 dB | 38.34 dB | 272,703 | — |
| WIRE | 40.24 dB | 38.90 dB | 265,523 | 835 |
| SMN (Ours) | 41.40 dB | 42.53 dB | 264,216 | 208 |
SMN achieves the highest PSNR on both datasets with fewer parameters than all baselines and 4× lower GFLOPs than WIRE.
3D NeRF Novel View Synthesis (avg. over 8 scenes, 400×400)
| Method | Average PSNR | Parameters |
|---|---|---|
| PE + WIRE | 25.14 dB | 283,479 |
| PE + MLP | 26.66 dB | 290,370 |
| PE + RINR | 26.84 dB | 314,703 |
| PE + SIREN | 29.06 dB | 287,749 |
| PE + Gauss | 32.00 dB | 287,749 |
| PE + SMN (Ours) | 32.98 dB | 287,749 |
PE = Positional Encoding. SMN outperforms the next-best method (PE + Gauss) by +0.98 dB on average across all 8 NeRF scenes.
Visual Comparison — 2D Image Reconstruction






Magnified crops from Kodak. SMN preserves fine textures and edge details most faithfully among all methods.
Ablation Study
Modulation Mechanism (Kodak)
Multiplicative masking yields a +1.15 dB gain — confirming the importance of spectral sculpting over simple addition.
Learnable Sine Layer Variants (Kodak)
Each additional learnable basis consistently improves performance; K=3 is selected as the final design.
Citation
@inproceedings{wang2026smn,
title = {Subtractive Modulative Network with Learnable Periodic Activations},
author = {Wang, Tiou and Yang, Zhuoqian and Flierl, Markus and
Salzmann, Mathieu and S{\"u}sstrunk, Sabine},
booktitle = {Proceedings of ICASSP},
year = {2026}
}